Alex R recently discovered interesting thing: in SQL pipelined functions work much faster than simple non-pipelined table functions, so if you already have simple non-pipelined table function and want to get its results in sql (select * from table(fff)), it’s much better to create another pipelined function which will get and return its results through PIPE ROW().
A bit more details:
Assume we need to return collection “RESULT” from PL/SQL function into SQL query “select * from table(function_F(…))”.
If we create 2 similar functions: pipelined f_pipe and simple non-pipelined f_non_pipe,
create or replace function f_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
begin
...
for i in 1..n loop
pipe row (result(i));
end loop;
end f_pipe;
/
create or replace function f_non_pipe(n int) return tt_id_value
as
result tt_id_value;
begin
...
return result;
end f_non_pipe;
/
create or replace type to_id_value as object (id int, value int)
/
create or replace type tt_id_value as table of to_id_value
/
create or replace function f_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
for i in 1..n loop
pipe row (result(i));
end loop;
end f_pipe;
/
create or replace function f_non_pipe(n int) return tt_id_value
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
return result;
end f_non_pipe;
/
create or replace function f_pipe_for_nonpipe(n int) return tt_id_value pipelined
as
result tt_id_value;
begin
result:=f_non_pipe(n);
for i in 1..result.count loop
pipe row (result(i));
end loop;
end;
/
create or replace function f_udf_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
for i in 1..n loop
pipe row (result(i));
end loop;
end;
/
create or replace function f_udf_non_pipe(n int) return tt_id_value
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
return result;
end;
/
set echo on feed only timing on;
--alter session set optimizer_adaptive_plans=false;
--alter session set "_optimizer_use_feedback"=false;
select sum(id * value) s from table(f_pipe(&1));
select sum(id * value) s from table(f_non_pipe(&1));
select sum(id * value) s from table(f_pipe_for_nonpipe(&1));
select sum(id * value) s from table(f_udf_pipe(&1));
select sum(id * value) s from table(f_udf_non_pipe(&1));
with function f_inline_non_pipe(n int) return tt_id_value
as
result tt_id_value;
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
return result;
end;
select sum(id * value) s from table(f_inline_non_pipe(&1));
/
set timing off echo off feed on;
we’ll find that the function with simple “return result” works at least twice slower than pipelined function:
| Function | 1 000 000 elements | 100 000 elements |
|---|---|---|
| F_PIPE | 2.46 | 0.20 |
| F_NON_PIPE | 4.39 | 0.44 |
| 2.61 | 0.26 | |
| F_UDF_PIPE | 2.06 | 0.20 |
| F_UDF_NON_PIPE | 4.46 | 0.44 |
I was really surprised that even “COLLECTION ITERATOR PICKLER FETCH” with F_PIPE_FOR_NONPIPE that gets result of F_NON_PIPE and returns it through PIPE ROW() works almost twice faster than F_NON_PIPE, so I decided to analyze it using stapflame by Frits Hoogland.
I added “dbms_lock.sleep(1)” into both of these function after collection generation, to compare the difference only between “pipe row” in loop and “return result”:
create or replace function f_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
dbms_lock.sleep(1);
for i in 1..n loop
pipe row (result(i));
end loop;
end f_pipe;
/
create or replace function f_non_pipe(n int) return tt_id_value
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
dbms_lock.sleep(1);
return result;
end f_non_pipe;
/
And stapflame showed that almost all overhead was consumed by the function “kgmpoa_Assign_Out_Arguments”:
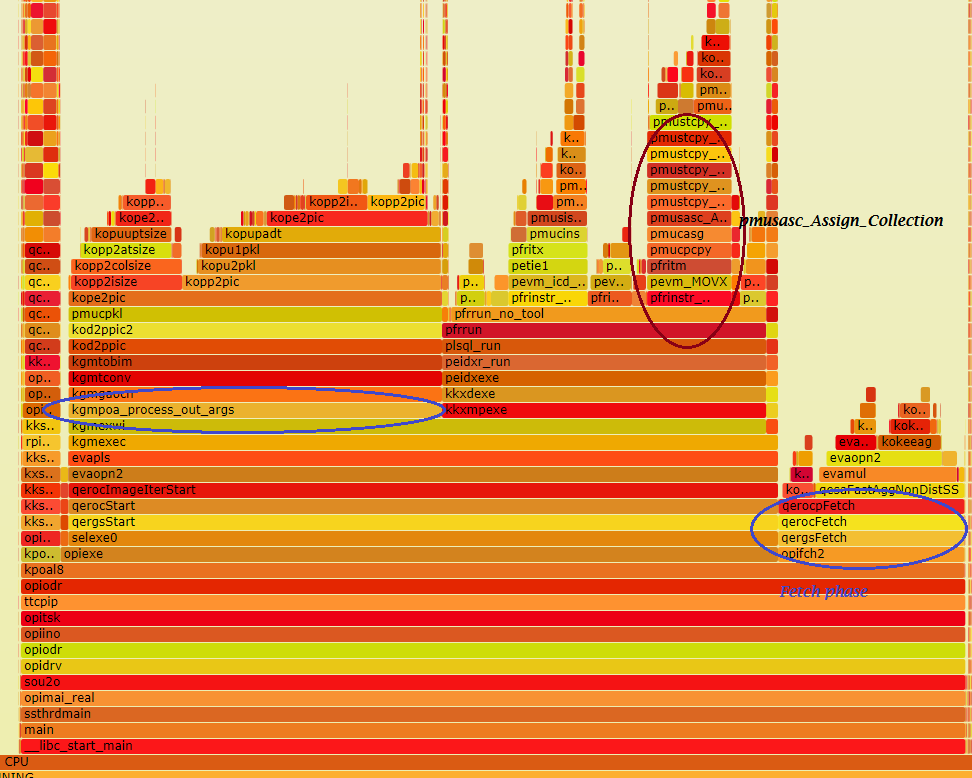
I don’t know what this function is doing exactly, but we can see that oracle assign collection a bit later.
From other functions in this stack(pmucpkl, kopp2isize, kopp2colsize, kopp2atsize(attribute?), kopuadt) I suspect that is some type of preprocessiong of return arguments.
What do you think about it?
Full stapflame output:
stapflame_nonpipe
stapflame_pipe