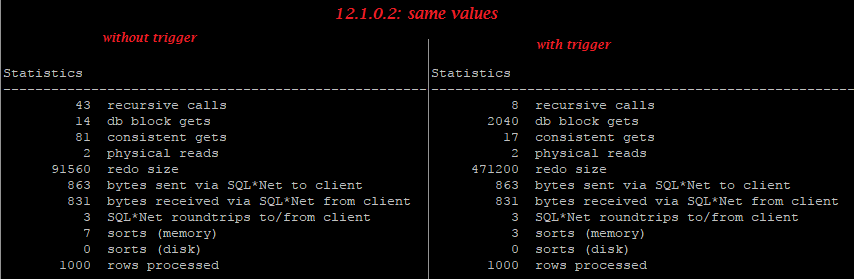
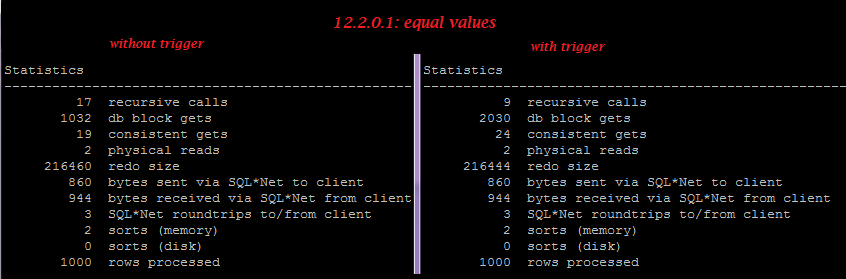
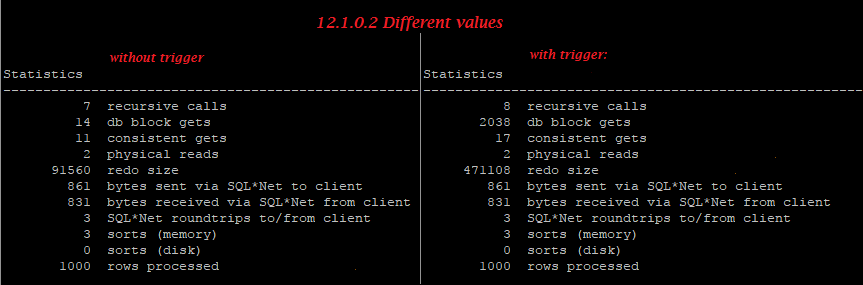
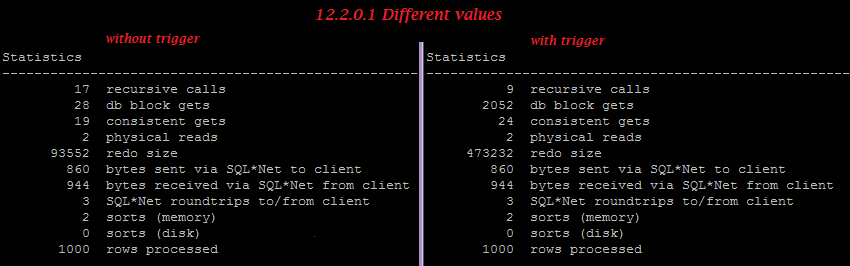
Three interesting myths about rowlimiting clause vs rownum have recently been posted on our Russian forum:
- TopN query with rownum<=N is always faster than "fetch first N rows only" (ie. row_number()over(order by ...)<=N)
- “fetch first N rows only” is always faster than rownum<=N
- “SORT ORDER BY STOPKEY” stores just N top records during sorting, while “WINDOW SORT PUSHED RANK” sorts all input and stores all records sorted in memory.
Interestingly that after Vyacheslav posted first statement as an axiom and someone posted old tests(from 2009) and few people made own tests which showed that “fetch first N rows” is about 2-3 times faster than the query with rownum, the final decision was that “fetch first” is always faster.
First of all I want to show that statement #3 is wrong and “WINDOW SORT PUSHED RANK” with row_number works similarly as “SORT ORDER BY STOPKEY”:
It’s pretty easy to show using sort trace:
Let’s create simple small table Tests1 with 1000 rows where A is in range 1-1000 (just 1 block):
create table test1(a not null, b) as
select level, level from dual connect by level<=1000;
alter session set max_dump_file_size=unlimited;
ALTER SESSION SET EVENTS '10032 trace name context forever, level 10';
ALTER SESSION SET tracefile_identifier = 'rownum';
select * from (select * from test1 order by a) where rownum<=10;
ALTER SESSION SET tracefile_identifier = 'rownumber';
select * from test1 order by a fetch first 10 rows only;
And we can see from the trace files that both queries did the same number of comparisons:
rownum:
----- Current SQL Statement for this session (sql_id=bbg66rcbt76zt) -----
select * from (select * from test1 order by a) where rownum<=10
---- Sort Statistics ------------------------------
Input records 1000
Output records 10
Total number of comparisons performed 999
Comparisons performed by in-memory sort 999
Total amount of memory used 2048
Uses version 1 sort
---- End of Sort Statistics -----------------------
[collapse]
row_number
----- Current SQL Statement for this session (sql_id=duuy4bvaz3d0q) -----
select * from test1 order by a fetch first 10 rows only
---- Sort Statistics ------------------------------
Input records 1000
Output records 10
Total number of comparisons performed 999
Comparisons performed by in-memory sort 999
Total amount of memory used 2048
Uses version 1 sort
---- End of Sort Statistics -----------------------
[collapse]
Ie. each row (except first one) was compared with the biggest value from top 10 values and since they were bigger than top 10 value, oracle doesn’t compare it with other TopN values.
And if we change the order of rows in the table both of these queries will do the same number of comparisons again:
from 999 to 0
create table test1(a not null, b) as
select 1000-level, level from dual connect by level<=1000;
alter session set max_dump_file_size=unlimited;
ALTER SESSION SET EVENTS '10032 trace name context forever, level 10';
ALTER SESSION SET tracefile_identifier = 'rownum';
select * from (select * from test1 order by a) where rownum<=10;
ALTER SESSION SET tracefile_identifier = 'rownumber';
select * from test1 order by a fetch first 10 rows only;
[collapse]
rownum
----- Current SQL Statement for this session (sql_id=bbg66rcbt76zt) -----
select * from (select * from test1 order by a) where rownum<=10
---- Sort Statistics ------------------------------
Input records 1000
Output records 1000
Total number of comparisons performed 4976
Comparisons performed by in-memory sort 4976
Total amount of memory used 2048
Uses version 1 sort
---- End of Sort Statistics -----------------------
[collapse]
row_number
----- Current SQL Statement for this session (sql_id=duuy4bvaz3d0q) -----
select * from test1 order by a fetch first 10 rows only
---- Sort Statistics ------------------------------
Input records 1000
Output records 1000
Total number of comparisons performed 4976
Comparisons performed by in-memory sort 4976
Total amount of memory used 2048
Uses version 1 sort
---- End of Sort Statistics -----------------------
[collapse]
We can see that both queries required much more comparisons(4976) here, that’s because each new value is smaller than the biggest value from the topN and even smaller than lowest value, so oracle should get right position for it and it requires 5 comparisons for that (it compares with 10th value, then with 6th, 3rd, 2nd and 1st values from top10). Obviously it makes less comparisons for the first 10 rows.
Now let’s talk about statements #1 and #2:
We know that rownum forces optimizer_mode to switch to “first K rows”, because of the parameter “_optimizer_rownum_pred_based_fkr”
SQL> @param_ rownum
NAME VALUE DEFLT TYPE DESCRIPTION
---------------------------------- ------ ------ --------- ------------------------------------------------------
_optimizer_rownum_bind_default 10 TRUE number Default value to use for rownum bind
_optimizer_rownum_pred_based_fkr TRUE TRUE boolean enable the use of first K rows due to rownum predicate
_px_rownum_pd TRUE TRUE boolean turn off/on parallel rownum pushdown optimization
while fetch first/row_number doesn’t (it will be changed after the patch #22174392) and it leads to the following consequences:
1. first_rows disables serial direct reads optimization(or smartscan on Exadata), that’s why the tests with big tables showed that “fetch first” were much faster than the query with rownum.
So if we set “_serial_direct_read”=always, we get the same performance in both tests (within the margin of error).
2. In cases when index access (index full scan/index range scan) is better, CBO differently calculates the cardinality of underlying INDEX FULL(range) SCAN:
the query with rownum is optimized for first_k_rows and the cardinality of index access is equal to K rows, but CBO doesn’t reduce cardinality for “fetch first”, so the cost of index access is much higher, compare them:
rownum
SQL> explain plan for
2 select *
3 from (select * from test order by a,b)
4 where rownum<=10;
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 390 | 4 (0)| 00:00:01 |
|* 1 | COUNT STOPKEY | | | | | |
| 2 | VIEW | | 10 | 390 | 4 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| TEST | 1000K| 12M| 4 (0)| 00:00:01 |
| 4 | INDEX FULL SCAN | IX_TEST_AB | 10 | | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(ROWNUM<=10)
[collapse]
fetch first
SQL> explain plan for
2 select *
3 from test
4 order by a,b
5 fetch first 10 rows only;
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 780 | | 5438 (1)| 00:00:01 |
|* 1 | VIEW | | 10 | 780 | | 5438 (1)| 00:00:01 |
|* 2 | WINDOW SORT PUSHED RANK| | 1000K| 12M| 22M| 5438 (1)| 00:00:01 |
| 3 | TABLE ACCESS FULL | TEST | 1000K| 12M| | 690 (1)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("from$_subquery$_002"."rowlimit_$$_rownumber"<=10)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "TEST"."A","TEST"."B")<=10)
[collapse]
fetch first + first_rows
SQL> explain plan for
2 select/*+ first_rows */ *
3 from test
4 order by a,b
5 fetch first 10 rows only;
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 780 | 27376 (1)| 00:00:02 |
|* 1 | VIEW | | 10 | 780 | 27376 (1)| 00:00:02 |
|* 2 | WINDOW NOSORT STOPKEY | | 1000K| 12M| 27376 (1)| 00:00:02 |
| 3 | TABLE ACCESS BY INDEX ROWID| TEST | 1000K| 12M| 27376 (1)| 00:00:02 |
| 4 | INDEX FULL SCAN | IX_TEST_AB | 1000K| | 2637 (1)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("from$_subquery$_002"."rowlimit_$$_rownumber"<=10)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "TEST"."A","TEST"."B")<=10)
[collapse]
fetch first + index
SQL> explain plan for
2 select/*+ index(test (a,b)) */ *
3 from test
4 order by a,b
5 fetch first 10 rows only;
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 780 | 27376 (1)| 00:00:02 |
|* 1 | VIEW | | 10 | 780 | 27376 (1)| 00:00:02 |
|* 2 | WINDOW NOSORT STOPKEY | | 1000K| 12M| 27376 (1)| 00:00:02 |
| 3 | TABLE ACCESS BY INDEX ROWID| TEST | 1000K| 12M| 27376 (1)| 00:00:02 |
| 4 | INDEX FULL SCAN | IX_TEST_AB | 1000K| | 2637 (1)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("from$_subquery$_002"."rowlimit_$$_rownumber"<=10)
2 - filter(ROW_NUMBER() OVER ( ORDER BY "TEST"."A","TEST"."B")<=10)
[collapse]
So in this case we can add hints “first_rows” or “index”, or install
the patch #22174392.
ps. I thought to post this note later, since I hadn’t time enough to add other interesting details about the different TopN variants, including “with tie”, rank(), etc, so I’ll post another note with more details later.