You can always download latest version here: http://github.com/xtender/xt_scripts/blob/master/dynamic_sampling_used_for.sql
Current source code:
col owner for a30;
col tab_name for a30;
col top_sql_id for a13;
col temporary for a9;
col last_analyzed for a30;
col partitioned for a11;
col nested for a6;
col IOT_TYPE for a15;
with tabs as (
select
to_char(regexp_substr(sql_fulltext,'FROM "([^"]+)"."([^"]+)"',1,1,null,1)) owner
,to_char(regexp_substr(sql_fulltext,'FROM "([^"]+)"."([^"]+)"',1,1,null,2)) tab_name
,count(*) cnt
,sum(executions) execs
,round(sum(elapsed_time/1e6),3) elapsed
,max(sql_id) keep(dense_rank first order by elapsed_time desc) top_sql_id
from v$sqlarea a
where a.sql_text like 'SELECT /* OPT_DYN_SAMP */%'
group by
to_char(regexp_substr(sql_fulltext,'FROM "([^"]+)"."([^"]+)"',1,1,null,1))
,to_char(regexp_substr(sql_fulltext,'FROM "([^"]+)"."([^"]+)"',1,1,null,2))
)
select tabs.*
,t.temporary
,t.last_analyzed
,t.partitioned
,t.nested
,t.IOT_TYPE
from tabs
,dba_tables t
where
tabs.owner = t.owner(+)
and tabs.tab_name = t.table_name(+)
order by elapsed desc
/
col owner clear;
col tab_name clear;
col top_sql_id clear;
col temporary clear;
col last_analyzed clear;
col partitioned clear;
col nested clear;
col IOT_TYPE clear;
ps. Or if you want to find queries that used dynamic sampling, you can use query like that:
select s.*
from v$sql s
where
s.sql_id in (select p.sql_id
from v$sql_plan p
where p.id=1
and p.other_xml like '%dynamic_sampling%'
)




 Simple oracle client for android
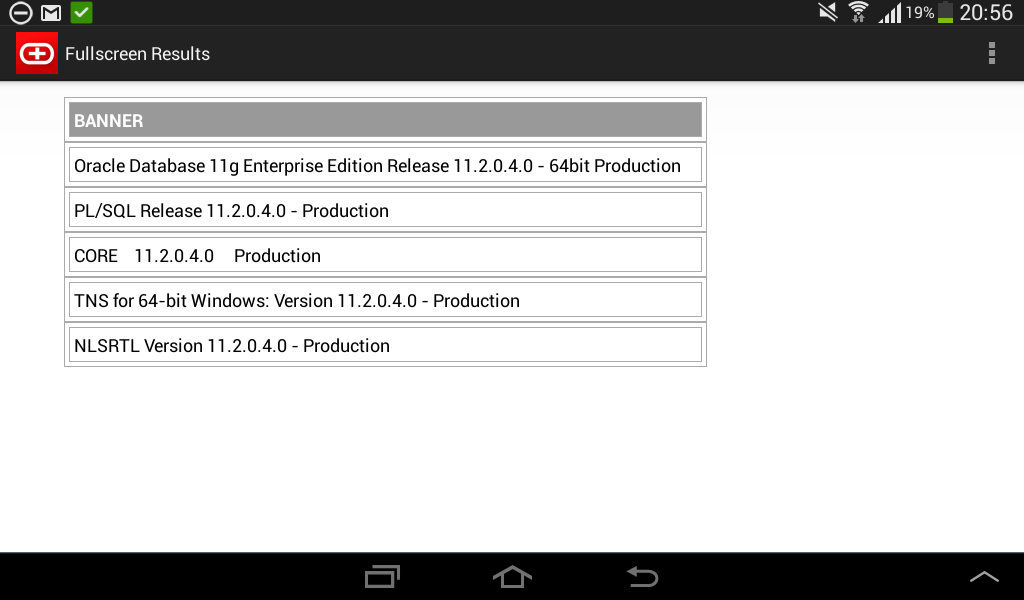
Simple oracle client for android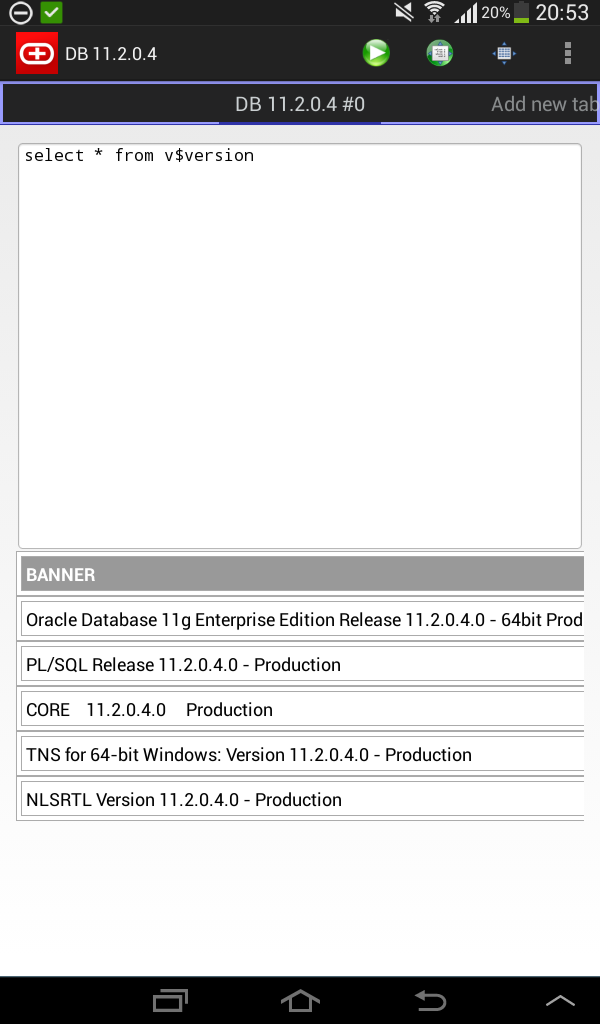
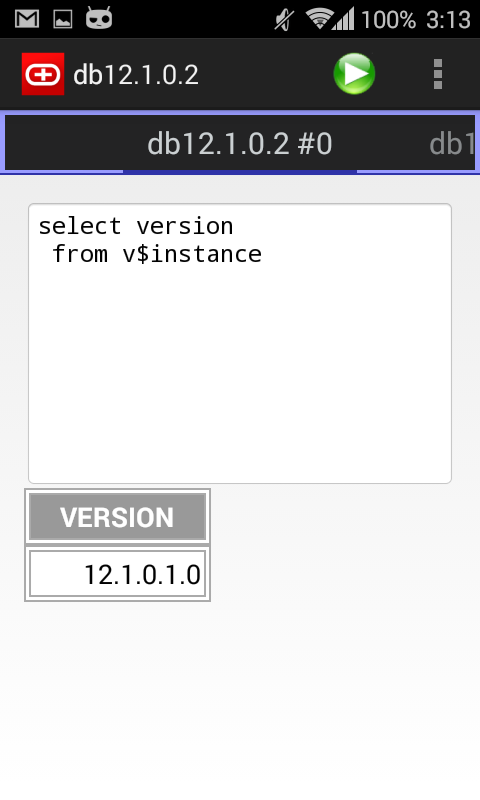

 ), they will not be cached :
), they will not be cached :